Tutorials
Step-by-step tutorials on Python scrapers, Reddit APIs, Google Trends, RAG pipelines, and job data. Real production code, tested patterns.
40 articles
How to Scrape AmbitionBox Company Reviews and Ratings
AmbitionBox is India largest employer review platform with 300,000 companies. Learn how to pull ratings, review counts, salary data, and dimension scores as structured JSON without any official API.
AliExpress Product Data API: Prices, Ratings, and Orders in Python
AliExpress affiliate API has restricted coverage. Learn how to scrape AliExpress product listings for prices, ratings, order counts, and seller data as structured JSON — no affiliate approval needed.
ClinicalTrials.gov API v2: How to Search 500,000 Studies and Track Trial Status
ClinicalTrials.gov upgraded to a v2 REST API in 2024. Here is how to use it, what changed from v1, and how to build automated trial monitoring pipelines in Python.
CourtListener API: How to Search US Court Records and Case Law Programmatically
CourtListener exposes 10M+ court opinions and dockets via a free REST API. Here is how to query it, what the rate limits actually are, and when a scraper is faster.

Crossref API: 150 Million DOIs, Citation Counts, and Bibliographic Data for Free
Crossref is the canonical DOI resolver for 150M+ scholarly works. The REST API returns publication metadata, reference lists, and citation counts with no authentication.
FDA Recall Data API: How to Monitor Drug, Device, and Food Recalls Programmatically
openFDA exposes drug recalls, device recalls, and food safety enforcement actions via a REST API. Here is how the endpoints work and what the data actually contains.
Federal Register API: How to Track US Rules, Proposed Rules, and Executive Orders
The Federal Register publishes every US executive action, proposed rule, and final rule via a REST API. Here is how to query it and what the data contains.
How to Scrape Google News in Python (No API Key Required)
Google killed its News API in 2013. Learn how to pull headlines, sources, and publication dates from Google News in Python using the RSS feed, the GNews approach, and a pay-per-result scraper.
Google Trends API for Python in 2025: pytrends vs Scraper
Google Trends has no official API. Learn why pytrends breaks, how the SERP API approach works, and the fastest way to pull trend data into Python without getting rate-limited.
India Government Data API: How to Pull Any data.gov.in Dataset Without the Documentation Confusion
data.gov.in has 10,000+ datasets including mandi prices, foreign trade, and census data. The OGD API works but has quirks that are not documented anywhere.
Instagram Profile Data Without the Meta API: Followers, Bio, and Posts at Scale
Meta restricts the Instagram Graph API to your own accounts. For researching public third-party profiles at scale, here is what data is available and how to collect it.
How to Scrape LinkedIn Employees Without Login or Sales Navigator
LinkedIn has no public API for employee data. Learn how to pull B2B leads, employee lists, and org chart data from LinkedIn company pages without a LinkedIn account or Sales Navigator subscription.
How to Scrape Naukri.com Jobs in Python (Structured JSON with Salaries)
Naukri.com has no public API. Learn how to scrape India's #1 job board for titles, companies, salary ranges, skills, experience, and work mode as structured JSON with pay-per-result pricing.
NPI Registry API: How to Look Up Any US Healthcare Provider Programmatically
CMS publishes the National Provider Identifier registry as a free API. Here is how to search by provider name, specialty, location, and NPI number — and what the data contains.
OpenAlex API: 250 Million Research Papers, Free, No Rate-Limit Workarounds Needed
OpenAlex replaced the defunct Microsoft Academic Graph with 250M+ scholarly works. The API is free, well-documented, and returns structured data including citations and author affiliations.
How to Search SEC EDGAR Filings by Keyword (Full-Text Search API)
SEC EDGAR has a free full-text search API called EFTS. Learn how to search 10-K, 10-Q, and 8-K filings by keyword, filter by form type and date, and extract matched text with Python.
Socrata API: How to Pull CDC, HHS, NYC, and 200+ Government Data Portals
Socrata powers data portals for the CDC, HHS, Chicago, New York City, Texas, and 200+ other government entities. One API, same query syntax, all of them.
How to Scrape Trustpilot Reviews by Company Domain (Python Guide)
Trustpilot has no public API for review data. Learn how to pull business reviews, star ratings, trust scores, and business replies from any Trustpilot company page using Python.

Threads Has No Public API: Here Is How to Get Profile and Post Data Anyway
Meta has not released a public Threads API. Here is what the data looks like, what fields are available via scraping, and how to collect it without getting blocked.
USASpending.gov API: How to Pull Federal Contracts, Grants, and Awards Programmatically
USASpending.gov tracks every federal dollar spent. The API is public and free but the endpoint structure is non-obvious. Here is how to actually use it in Python.
World Bank API in Python 2025: GDP, Inflation, and 1,400 Indicators Without the SOAP Hell
The World Bank has a REST API but it returns XML by default, uses quirky pagination, and has undocumented quirks. Here is how to actually use it in Python.
World Bank Trade Data API: How to Pull Global Import and Export Statistics
The World Bank WITS database covers bilateral trade flows between 200+ countries. Here is how to access it programmatically and what the data actually contains.

Pull SEC Filings into a RAG Pipeline with Claude and the SEC EDGAR Scraper
How to turn 10-K, 10-Q and 8-K filings into a clean, chunked, citation-grounded knowledge base an LLM can answer questions over

Scraping Reddit Comments and Full Thread Trees in 2025
Reddit's nested comment structure is complex to collect correctly. This guide covers the complete API approach for deep comment trees, deleted comments

How to Export Google Trends Data at Scale for Market Research
Exporting Google Trends for dozens or hundreds of keywords while avoiding rate limits, handling the normalization quirks

The Agentic Data Stack 2025: How to Pick the Right Scrapers for Your AI Workflow
A practical guide to building grounded AI agents with real-time scraped data. Which data sources matter for which agent types

Building a RAG Pipeline on SEC EDGAR Filings: A Step-by-Step Guide
How to scrape SEC EDGAR filings, chunk them for vector search, and build a provenance-aware Q&A system that cites specific filing sections using Claude.

Building an Automated Naukri Job Alert System with Python
How to build a custom Naukri job monitoring system that filters by salary, location, and skills — and sends instant alerts when relevant jobs post.

Build a Social Listening Agent for Threads with Claude
Use Apify's Threads Scraper with Claude to automate trend detection, brand monitoring, and content ideation from Meta's Threads platform.

Build a Custom Knowledge Base Chatbot with Claude and the RAG Crawler
Use Apify's RAG Crawler to ingest any website into a vector database, then wire Claude to answer questions against it.
Build an India Job Market Intelligence Tool with Claude and the Naukri Scraper
Use Apify's Naukri Jobs scraper with Claude to automate salary benchmarking, skills demand analysis, and hiring trend tracking for the Indian tech market.
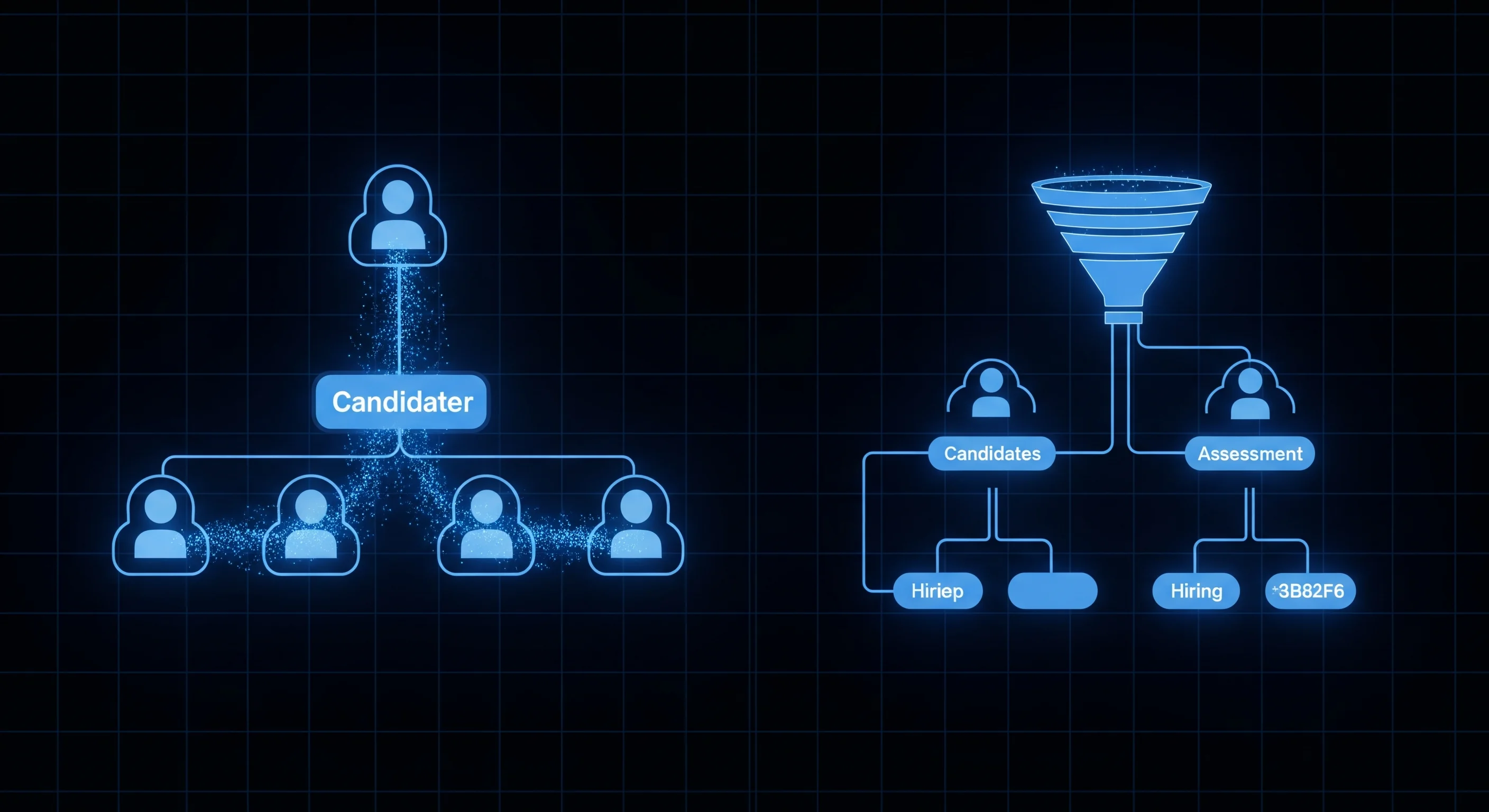
Build a Talent Intelligence System with Claude and ATS Job Scrapers
Combine Greenhouse, Lever, and Ashby job data with Claude to automate candidate sourcing research, salary benchmarking, skills gap analysis

Automate SEO Research and Content Strategy with Claude and Google Trends Pro
Use Apify's Google Trends Pro actor with Claude to build an autonomous content calendar generator, keyword opportunity finder
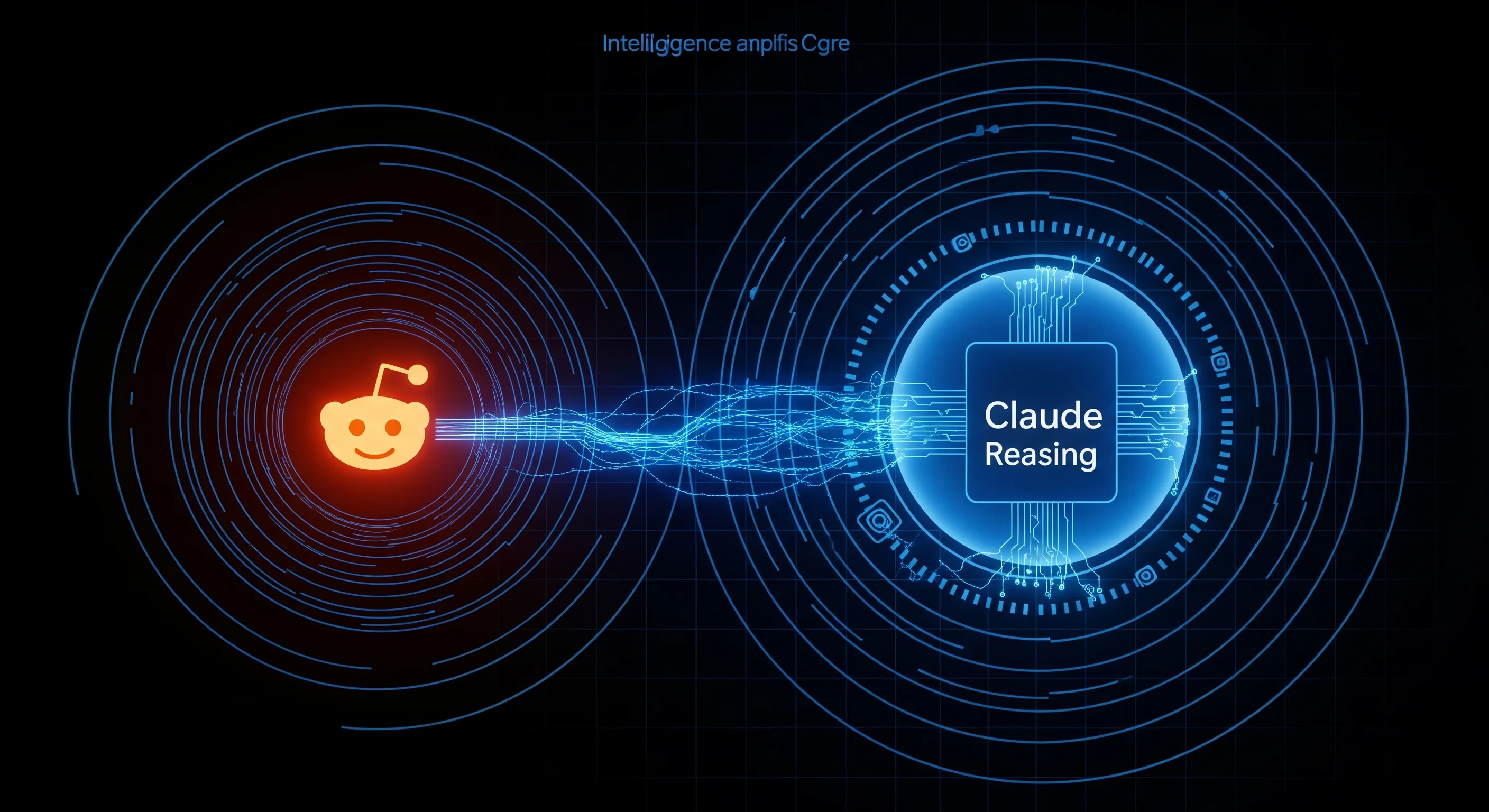
Build a Reddit Intelligence Agent with Claude and the Reddit Scraper
How to combine Apify's Reddit Scraper with Claude to build an autonomous brand monitoring agent, sentiment analysis pipeline
How to Aggregate Job Postings from 500+ Companies Using Public ATS APIs
Greenhouse, Lever, and Ashby expose zero-auth public job board APIs. This guide shows how to build a job aggregator that pulls from all three and
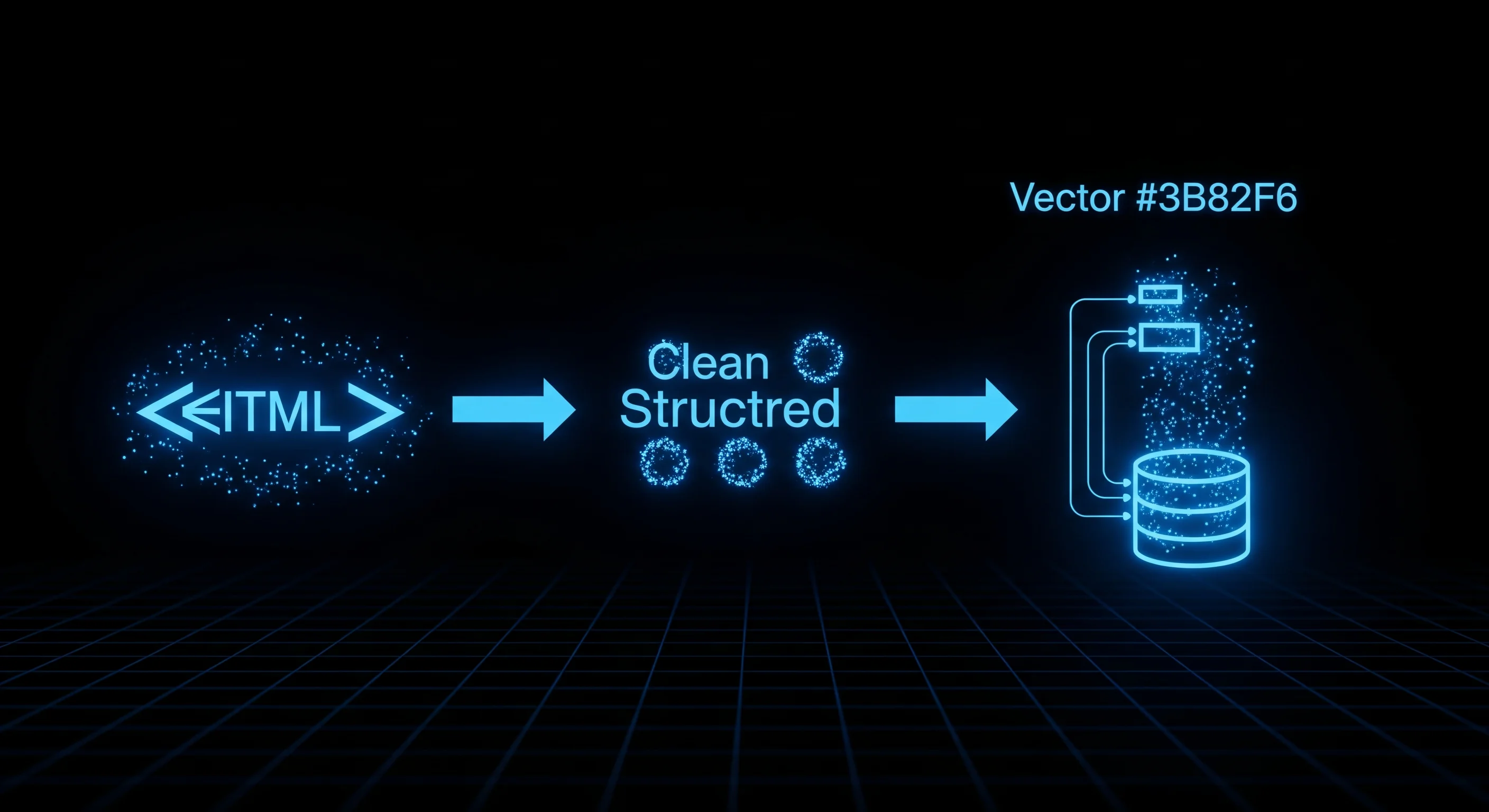
How to Build a RAG Pipeline Using Web-Scraped Content
A complete guide to turning any website into LLM context — from crawling and chunking to embedding, retrieval, and keeping the index fresh.
How to Scrape Meta Threads Data in 2025 (Without Getting Blocked)
Meta Threads has no public API for third-party developers. This guide shows the current working approaches for extracting profile data, post content

Naukri API 2025: How to Programmatically Access India's Largest Job Board
Naukri has no public API. This guide covers the session-warming approach that bypasses Akamai bot detection
Google Trends API Python 2025: Why pytrends Keeps Breaking (and What to Use Instead)
pytrends has been unreliable for years. We explain why Google Trends blocks HTTP clients, and show you three approaches that actually work in 2025.

How to Scrape Reddit Without an API Key in 2025
Reddit locked down its API in 2023. Here is every method that still works — OAuth, public client IDs, and scraper services — with code you can use today.