
Reddit Data for LLM Fine-Tuning: Quality, Licensing, and What Actually Works
Everything you need to know about using Reddit data for model training and fine-tuning — data quality patterns, filtering strategies
Build a Talent Intelligence System with Claude and ATS Job Scrapers
Combine Greenhouse, Lever, and Ashby job data with Claude to automate candidate sourcing research, salary benchmarking, skills gap analysis

From Raw HTML to Clean Dataset: Data Pipeline Architecture for AI Teams
The full architecture for a production-grade web data pipeline — collection, validation, transformation, storage, and freshness management.

Automate SEO Research and Content Strategy with Claude and Google Trends Pro
Use Apify's Google Trends Pro actor with Claude to build an autonomous content calendar generator, keyword opportunity finder

Social Media Data for AI: Reddit, Threads, and the Open Web
Where to get social media data for LLM training, fine-tuning, and RAG pipelines. A developer-focused breakdown of what is accessible, what it costs

How to Build a Competitor Intelligence System Using Web Scrapers
A practical guide to building automated competitor monitoring — pricing, job postings, content, and review tracking
Build a Reddit Intelligence Agent with Claude and the Reddit Scraper
How to combine Apify's Reddit Scraper with Claude to build an autonomous brand monitoring agent, sentiment analysis pipeline

India Tech Hiring Trends 2025: What the Job Data Actually Shows
We analyzed 50,000+ Naukri job postings to surface real patterns in India tech hiring — which skills are surging, which cities are growing
Pay-Per-Result vs Subscription Scraping: Why Billing Models Matter More Than You Think
Most scraping tools charge per run or per month — you pay whether data comes back or not. Here's why PPE billing changes the economics of every data
The Best Apify Actors for AI and LLM Projects in 2025
A curated list of Apify actors that ship data in formats LLMs can directly use — ranked by reliability, output quality, and billing fairness.
How to Aggregate Job Postings from 500+ Companies Using Public ATS APIs
Greenhouse, Lever, and Ashby expose zero-auth public job board APIs. This guide shows how to build a job aggregator that pulls from all three and
Using Google Trends Data for Market Research: A Developer's Playbook
How to extract actionable market intelligence from Google Trends — keyword validation, seasonal demand forecasting
Reddit Sentiment Analysis Pipeline: From Raw Posts to Actionable Insights
How to build a production sentiment analysis pipeline using Reddit data — scraping, preprocessing, classification
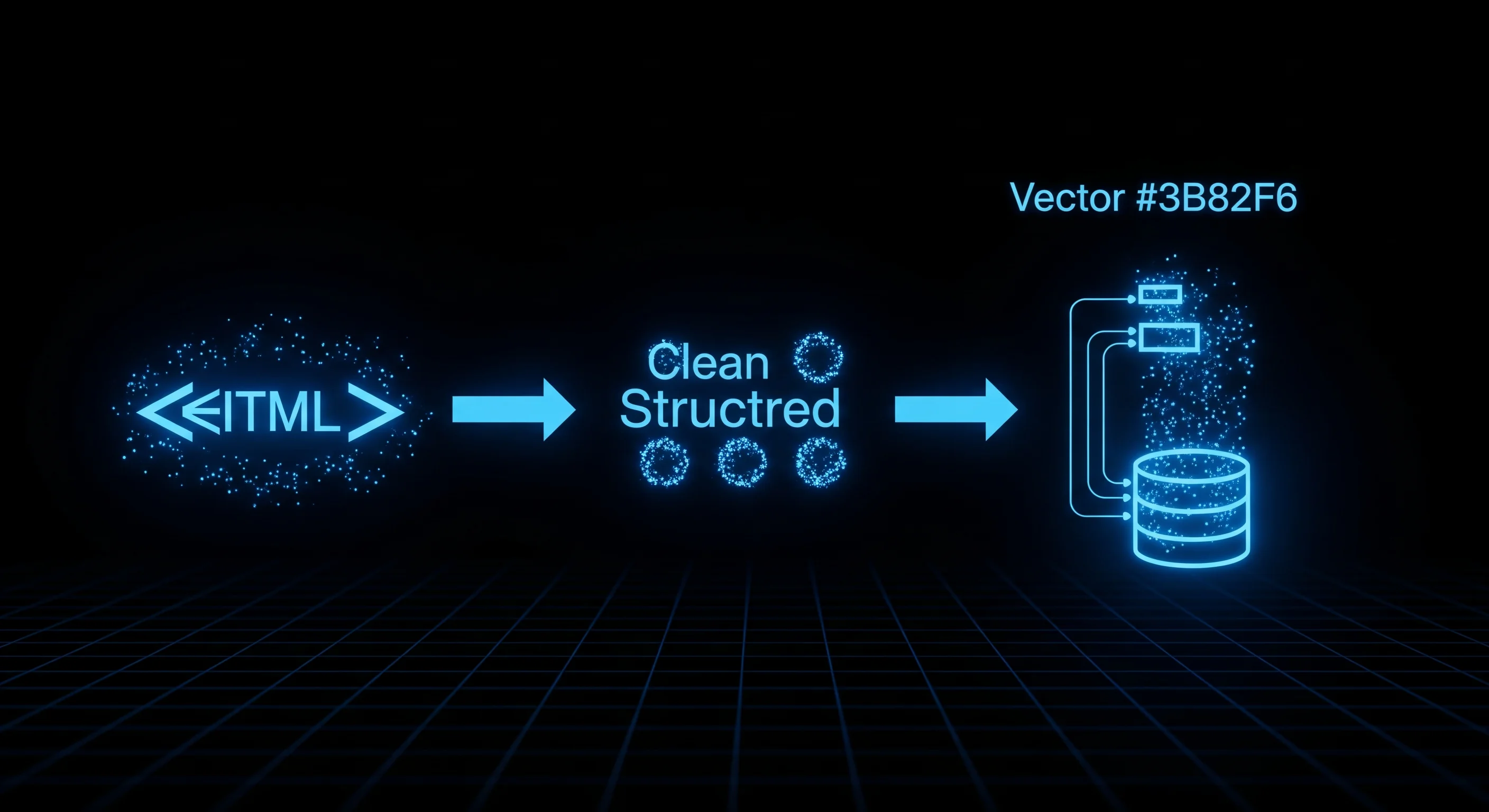
How to Build a RAG Pipeline Using Web-Scraped Content
A complete guide to turning any website into LLM context — from crawling and chunking to embedding, retrieval, and keeping the index fresh.

Web Scraping Without Getting Blocked in 2025: Proxies, Stealth, and Session Strategy
A technical guide to bypassing the five most common anti-bot systems — Cloudflare, Akamai, DataDome, PerimeterX, and reCAPTCHA

Apify vs Bright Data vs ScraperAPI vs Oxylabs: The 2025 Data Platform Comparison
We compared the four major web scraping platforms on pricing, ease of use, anti-bot capability, and proxy quality.

How to Scrape Meta Threads Data in 2025 (Without Getting Blocked)
Meta Threads has no public API for third-party developers. This guide shows the current working approaches for extracting profile data, post content

Firecrawl Alternative: Web Crawling for RAG Without the $50/Month Tax
Firecrawl is popular but expensive at scale. Here is a direct comparison of every web crawling option for RAG pipelines